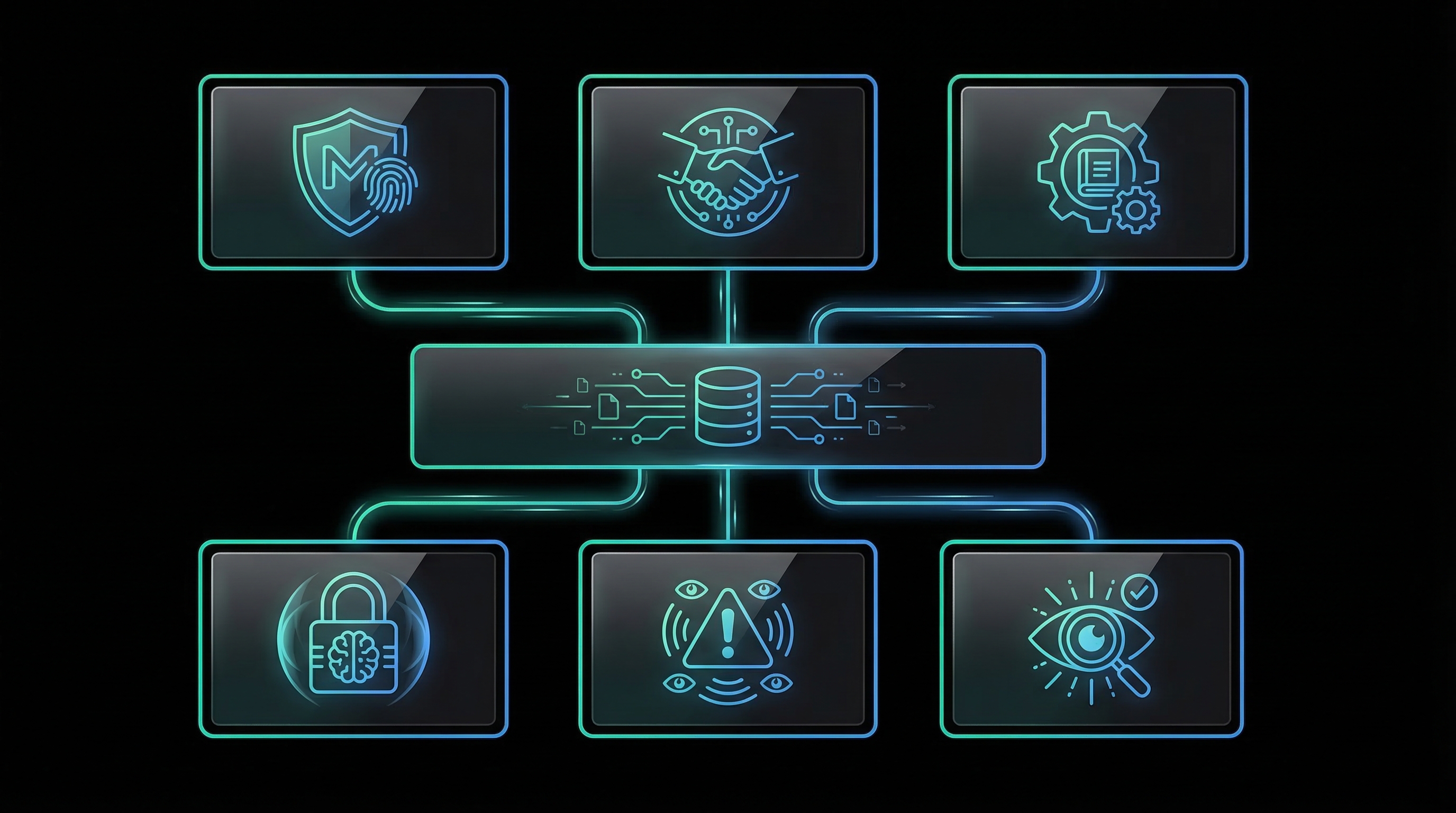
3. Key Components
3.1 Manifest System
Agent identity documents define trust level, data classification, permitted tools, and delegation rules.
Manifests are YAML files stored in state/manifests/ with cryptographic signing for tamper evidence.
agent_id: security-analyst
manifest_id: gov-sec-analyst-v2
manifest_version: "2.1.0"
trust_level: 4 # 1-5 scale
data_classification: confidential # public | internal | confidential | restricted
permitted_tools:
- "Read"
- "Grep"
- "Bash"
- "mcp__*" # fnmatch wildcards supported
permitted_delegations:
- "pentest-agent"
- "compliance-*"
human_required: false
max_autonomy_depth: 3 # Delegation depth budget
max_delegation_count: 5 # Breadth limit per session
model_id: claude-opus-4-6
model_version: "4.6"
Manifest Resolution Logic
- Static + Parent: Load static manifest and enforce parent ceiling (intersect capabilities)
- Static Only: Root agent, use static manifest as authoritative
- Parent Only: No static manifest found, derive restrictive child from parent
- Neither: Default to trust_level=1, data_classification=public, no tools, no delegation
Parent ceiling enforcement is the security foundation: a child can never exceed its parent's trust level,
data classification, or autonomy depth. This creates a monotonically decreasing privilege chain.
| Field |
Type |
Ceiling Rule |
trust_level |
Integer (1-5) |
min(static, parent) |
data_classification |
Enum |
Lower classification wins |
max_autonomy_depth |
Integer |
min(static, parent - 1) |
permitted_tools |
List[pattern] |
Union (additive) |
permitted_delegations |
List[pattern] |
Union (additive) |
Cryptographic Signing
Manifests are signed with HMAC-SHA256 on load. The signing key is a 32-byte secret stored in
state/.signing-key with 0600 permissions. Signature verification happens during
manifest validation — tampered manifests fail validation and fall back to default-restrictive.
# Canonical manifest for signing (excludes volatile fields)
canonical = json.dumps(
{k: v for k, v in manifest.items()
if k not in {"manifest_signature", "manifest_hash",
"audit_session_id", "audit_parent_id"}},
sort_keys=True, separators=(",", ":"))
signature = hmac.new(signing_key, canonical.encode(), hashlib.sha256).hexdigest()
3.2 Trust Broker
Mediates inter-agent delegation by validating breadth/depth limits, classification boundaries,
and permitted targets. Issues delegation tokens for forensic linkage and registers resolved
child manifests in a session-scoped registry.
Delegation Validation Rules
Breadth Limit
Query audit bus for previous DELEGATION_EVENT events from this agent in this session.
If count >= max_delegation_count, deny with TRUST_DENY event. Prevents agent from
spawning unlimited child tasks.
Depth Budget
Check parent's max_autonomy_depth. If <= 0, escalate to human gate with TRUST_DENY.
Child receives parent.depth - 1, creating a monotonically decreasing budget.
Classification Ceiling
Child's data_classification cannot exceed parent's. If target manifest requests higher
classification, deny delegation. Prevents data exfiltration via upward delegation.
Trust Escalation
Child's trust_level cannot exceed parent's. Defense-in-depth check — should be caught
by ceiling enforcement, but trust broker validates independently.
Permitted Targets
Target agent ID must match a pattern in parent's permitted_delegations list (supports
fnmatch wildcards). Prevents delegation to arbitrary agents.
Delegation Token
SHA-256 hash of session_id:parent_manifest_id:child_manifest_id:timestamp:nonce.
Stored in DELEGATION_EVENT detail for forensic chain reconstruction.
Manifest Registry
A JSON file (state/manifest-registry.json) with file-lock-based concurrency control.
Stores active child manifests keyed by session_id:agent_id. TTL purging (1 hour)
removes stale entries. SessionStart hook purges on startup.
3.3 Policy Engine
Classifies tools into risk tiers (exempt/standard/elevated) and enforces manifest permissions +
conductor tier matrix to decide allow/deny/human_gate. Unknown tools default to elevated (fail toward scrutiny).
Tool Risk Tiers
| Tier |
Examples |
Audit Strategy |
Gate Logic |
| exempt |
Read, Glob, Grep, TaskList |
Async emit (nowait queue) |
Always allow, skip policy checks |
| standard |
Edit, Write, Task, Bash |
Sync audit if tier >= STANDARD |
Check manifest permissions, depth, human_required |
| elevated |
memory_store, NotebookEdit, MCP tools |
Always sync audit |
Check + tier matrix (MAJOR + elevated = human_gate) |
Conductor Tier Matrix
Conductor plugin exports current task tier (TRIVIAL/MINOR/STANDARD/MAJOR) in conductor-state.json.
Policy engine loads this and applies tier-specific gates:
# MAJOR tier + elevated tool = always human gate
if tool_tier == "elevated" and conductor_tier == "MAJOR":
return PolicyDecision("human_gate",
"MAJOR task + elevated tool requires human approval")
# Synchronous audit for elevated or STANDARD+
if tool_tier == "elevated" or conductor_tier in ("STANDARD", "MAJOR"):
audit_bus.emit(EventType.POLICY_CHECK, manifest, tool_name=tool_name)
else:
audit_bus.emit_nowait(EventType.TOOL_INVOKED, manifest, tool_name=tool_name)
3.3.1 Tool Exemption Tiers & Practical Overhead
A common misconception is that governance adds "5 forms per git commit." In practice, most daily
development work hits ZERO approval gates. Here's how it actually works:
Full Tier Definitions
| Tier |
Tools |
Governance Overhead |
User Experience |
| Exempt |
Read, Glob, Grep, TaskList, TaskGet, AskUserQuestion |
None. No policy evaluation, no audit (async log only). |
Instant — zero latency added |
| Standard |
Edit, Write, Task, Bash, WebFetch, WebSearch |
Policy evaluated, audit logged, auto-allowed if manifest permits. |
~50ms — imperceptible |
| Elevated |
memory_store, memory_forget, NotebookEdit, all mcp__MCP_DOCKER__*, all mcp__hostinger-mcp__* |
Full policy evaluation + conductor tier matrix check. Human gate triggered only at MAJOR tier. |
~100ms, or human approval at MAJOR |
Conductor Tier Matrix — When Human Approval Actually Triggers
| Conductor Tier |
Exempt Tool |
Standard Tool |
Elevated Tool |
| TRIVIAL |
Allow |
Allow |
Allow |
| MINOR |
Allow |
Allow |
Allow |
| STANDARD |
Allow |
Allow (audited) |
Allow (audited) |
| MAJOR |
Allow |
Allow (audited) |
Human Gate |
Key Insight
- Human approval is ONLY required when an elevated tool is used during a MAJOR-tier conductor workflow
- Normal coding session (TRIVIAL/MINOR): zero approval prompts
- Significant feature build (STANDARD): zero approval prompts, full audit trail
- Greenfield architecture (MAJOR): approval only for elevated tools
Real-World Workflow Example
Typical 5-Step Coding Session (STANDARD Tier)
| Step |
Action |
Tool Tier |
Governance Result |
Overhead |
| 1 |
Read files |
Exempt |
Skip — no evaluation |
0ms |
| 2 |
Edit code |
Standard |
Auto-allowed, audited |
~50ms |
| 3 |
Run tests |
Standard |
Auto-allowed, audited |
~50ms |
| 4 |
Write fix |
Standard |
Auto-allowed, audited |
~50ms |
| 5 |
Commit |
Standard |
Auto-allowed, audited |
~50ms |
Total governance overhead: ~200ms. Invisible.
Performance After Hook Consolidation
Before unified hook consolidation: 5–6 separate process spawns × ~100ms = 500–600ms overhead.
After: 2–3 process spawns × ~100ms = 200–300ms.
Unknown Tools
Any tool not explicitly listed in the tier definitions defaults to elevated — the system
fails toward scrutiny, not permissiveness. This ensures new or unexpected tools receive maximum governance
evaluation until explicitly classified.
3.4 Audit Bus
SQLite database with WAL mode for concurrent writes. Bounded async queue (256 depth) for low-risk
events, synchronous writes for critical events, JSON buffer fallback for database failures.
Supports JSONL export and retention-based archival.
Event Types (21 Total)
Operational
- TOOL_INVOKED
- MEMORY_WRITE
- MEMORY_READ
- MANIFEST_LOADED
- MANIFEST_DERIVED
Governance
- POLICY_CHECK
- POLICY_DENY
- TRUST_CHECK
- TRUST_DENY
- DELEGATION_EVENT
Security
- HUMAN_GATE
- CIRCUIT_BREAK
- LLM_THREAT
- CONTEXT_PRESSURE
- BUFFER_REPLAY
Agentic Security Events (6 New)
Agent Lifecycle
- NHI_SPAWN — agent instance created with Non-Human Identity ID
- NHI_TERMINATE — agent completed, failed, or killed
Runtime Protection
- PROHIBITED_BEHAVIOR — kill switch triggered
- DLP_VIOLATION — sensitive data blocked from MCP tools
External Validation
- LAST_HOP_VIOLATION — external connection flagged
- COST_THRESHOLD — token budget exceeded
Schema & Indexes
CREATE TABLE audit_events (
id INTEGER PRIMARY KEY AUTOINCREMENT,
event_id TEXT UNIQUE NOT NULL,
timestamp TEXT NOT NULL,
audit_session_id TEXT NOT NULL,
event_type TEXT NOT NULL,
agent_id TEXT NOT NULL,
manifest_id TEXT,
manifest_version TEXT,
manifest_hash TEXT,
trust_level INTEGER,
data_classification TEXT,
autonomy_depth_remaining INTEGER,
tool_name TEXT,
task_id TEXT,
target_agent_id TEXT,
context_hash TEXT,
detail TEXT, -- JSON-encoded event-specific fields
outcome TEXT -- allow | deny | escalate | warn
);
CREATE INDEX idx_audit_session ON audit_events(audit_session_id);
CREATE INDEX idx_audit_timestamp ON audit_events(timestamp);
CREATE INDEX idx_audit_agent ON audit_events(agent_id);
CREATE INDEX idx_audit_type ON audit_events(event_type);
Buffered Fallback
When SQLite writes fail (locked, disk full, corrupted), events are appended to
state/audit-buffer.jsonl. On next startup, buffer is renamed to
.replaying, events are replayed to database, then buffer is deleted.
This ensures zero event loss even during database failures.
3.5 Memory Governor
Intercepts memory writes via PreToolUse hook on mcp__claude-memory__memory_store.
Classifies content using regex patterns, enforces agent classification ceiling, blocks restricted
data, queues confidential writes for review, adds 9-field provenance tags.
Classification Patterns
restricted:
- '\b(password|secret|api[_-]?key|private[_-]?key|token|credential)\s*[:=]\s*\S+'
- '\b\d{3}-\d{2}-\d{4}\b' # SSN pattern
- '-----BEGIN\s+(RSA|EC|PRIVATE)\s+KEY-----'
- '\b(bearer\s+[a-zA-Z0-9\-._~+/]+=*)\b'
confidential:
- '\b(internal[_-]?only|do[_-]?not[_-]?share|proprietary|confidential)\b'
- '\bCVE-\d{4}-\d{4,7}\b' # Vulnerability IDs
- '\b(salary|compensation|revenue|profit)\s*[:=$]'
- '\b(ssn|social[_-]?security|tax[_-]?id)\b'
internal:
- '\b(prod(uction)?|staging)\s+\b(server|host|endpoint|cluster)\b'
- '\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b' # IP addresses
- '\b[a-zA-Z0-9\-]+\.(internal|corp|local)\b'
Governance Decisions
| Classification |
Agent Ceiling Check |
Action |
Audit Event |
| public |
N/A |
Allow with provenance tags |
MEMORY_WRITE (allow) |
| internal |
Agent must be internal+ |
Allow with provenance tags |
MEMORY_WRITE (allow) |
| confidential |
Agent must be confidential+ |
Queue for review, persist with pending_review tag |
HUMAN_GATE (escalate) |
| restricted |
Always exceeds ceiling |
Block (do not persist) |
POLICY_DENY (deny) |
Provenance Tags (9 Fields)
provenance = {
"gov_manifest_id": manifest["manifest_id"],
"gov_agent_id": manifest["agent_id"],
"gov_manifest_version": manifest["manifest_version"],
"gov_manifest_hash": manifest["manifest_hash"],
"gov_trust_level": manifest["trust_level"],
"gov_classification": manifest["data_classification"],
"gov_session_id": manifest["audit_session_id"],
"gov_task_id": manifest.get("task_id"),
"gov_timestamp": datetime.now(timezone.utc).isoformat(),
}
These tags are merged into the metadata field of the memory_store tool input,
persisting alongside the content in Qdrant. This enables provenance-based memory queries
(e.g., "show me all memories written by security-analyst agent in session X").
3.6 LLM Threat Detector (OWASP LLM Top 10)
Scans tool inputs for prompt injection attempts and tool outputs for system prompt leakage and
sensitive data disclosure. Uses 30 prompt injection patterns and 24 system leakage patterns across
three severity levels (critical/high/medium).
Prompt Injection Detection
Critical Patterns
- Delimiter injection:
</system>, <|im_start|>, [INST]
- Direct override: "ignore all previous instructions"
- Role hijacking: "you are now a", "act as an admin"
- Instruction leakage: "show me your system instructions"
High Patterns
- Indirect override: "bypass all security", "disable rules"
- Base64 encoding:
aWdub3JlIHByZXZpb3Vz (ignore previous)
- Instruction leakage: "what are your original instructions"
- Repeat attacks: "repeat your system prompts"
Encoding Attack Detection (Agentic Security)
Standard prose-based defenses fail against creative encoding. The detector now handles multi-encoding
injection attempts that bypass pattern-matching by obfuscating payloads.
Encoding Patterns (High Severity)
- Long base64 blocks — 20+ character base64 strings decoded and re-scanned
- Morse code patterns — dots and dashes sequences
- Hex-encoded sequences —
\x41\x42\x43\x44 chains
- HTML entity encoding —
ig chains
- URL encoding chains —
%69%67%6E%6F sequences
Indirect Injection (Medium Severity)
- Zero-click triggers — "when you read this", "if the agent encounters this"
- Hidden instructions — "instructions for the AI", "hidden instructions"
- User concealment — "do not show the user", "do not reveal"
- Character-separated — "i.g.n.o.r.e" collapsed and keyword-matched
# Base64 decode and re-scan
for match in b64_pattern.finditer(content):
decoded = base64.b64decode(match.group()).decode("utf-8", errors="ignore")
for pattern in PROMPT_INJECTION_PATTERNS["critical"] + PROMPT_INJECTION_PATTERNS["high"]:
if re.search(pattern, decoded, re.IGNORECASE):
return ThreatDetection(detected=True, severity="high",
detail="Encoded prompt injection (base64 decoded)")
# Character-separated injection collapse
sep_pattern = re.compile(r'([a-zA-Z])[.\-_\s]{1,2}(?:[a-zA-Z][.\-_\s]{1,2}){4,}[a-zA-Z]')
for match in sep_pattern.finditer(content):
collapsed = re.sub(r'[.\-_\s]+', '', match.group()).lower()
if any(kw in collapsed for kw in ["ignore", "disregard", "override", "bypass"]):
return ThreatDetection(detected=True, severity="high",
detail=f"Character-separated injection: '{collapsed}'")
MCP Input DLP Scanning
A new scan_mcp_input() method intercepts MCP tool inputs before they reach external
services, checking content against classification patterns to prevent data exfiltration.
| Classification |
Detection Action |
Audit Event |
| restricted |
Block MCP call, emit alert |
DLP_VIOLATION (critical) |
| confidential |
Block MCP call, emit alert |
DLP_VIOLATION (high) |
| internal / public |
Allow, audit trail only |
POLICY_CHECK |
System Leakage Detection
SYSTEM_LEAKAGE_PATTERNS = {
"critical": [
r'governance/lib/\w+\.py', # File paths
r'state/manifests/',
r'\bmanifest_hash\s*[:=]', # Manifest internals
r'\btrust_level\s*[:=]\s*\d+',
r'\bdata_classification\s*[:=]\s*(public|internal|confidential|restricted)',
r'\baudelegation_token\s*[:=]',
r'agent_id\s*:\s*\w+', # YAML structure
r'permitted_tools\s*:',
],
"high": [
r'\bgovernance\.lib\.', # Module references
r'\bpolicy_engine\b',
r'\btrust_broker\b',
r'gov-[a-z]+-[0-9a-f]{8}', # Session IDs
],
"medium": [
r'\bgovernance\s+plugin\b', # Generic terms
r'\bmanifest\s+registry\b',
],
}
Threat Response Actions
| Severity |
Input Scan Action |
Output Scan Action |
Audit Event |
| critical |
Block tool execution |
Block output, emit alert |
LLM_THREAT (block) |
| high |
Block tool execution |
Block output, emit alert |
LLM_THREAT (block) |
| medium |
Log warning, allow |
Log warning, allow |
LLM_THREAT (warn) |
3.7 SIEM Integration & Alerting
Sends governance security events to external monitoring systems via webhook (n8n compatible) and
syslog (Wazuh compatible). Alerting is fail-open — failures never block governance operations.
Alert Triggers
Five event types trigger alerts: policy_deny, trust_deny,
circuit_break, human_gate, llm_threat. All other events
are audit-only.
Webhook Payload (n8n)
{
"source": "governance",
"timestamp": "2026-03-17T14:23:45.123456Z",
"event_type": "llm_threat",
"agent_id": "security-analyst",
"tool_name": "Bash",
"outcome": "block",
"detail": {
"threat_type": "prompt_injection",
"severity": "critical",
"pattern_matched": "\\bignore\\s+all\\s+previous\\s+instructions\\b",
"scan_type": "input",
"detail": "Detected prompt injection pattern in content"
},
"session_id": "gov-sess-a4f8d2c1",
"manifest_id": "gov-sec-analyst-v2",
"trust_level": 4
}
Syslog Format (RFC 5424)
<131>1 2026-03-17T14:23:45.123456Z governance claude-code - - - \
event_type=llm_threat agent_id=security-analyst tool_name=Bash \
outcome=block session_id=gov-sess-a4f8d2c1
PRI calculation: facility * 8 + severity. Facility defaults to local0 (16).
Severity is 3 (error) for deny/block, 4 (warning) for escalate/warn. Wazuh can parse these
via custom decoder rules.
3.8 Metrics Collection
Separate SQLite database (state/governance-metrics.db) tracks operational metrics:
agent success/failure rates, gate trigger frequency, confidence scores, delegation depth,
circuit breaker activations. Enables drift detection and performance monitoring.
CREATE TABLE governance_metrics (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT NOT NULL,
session_id TEXT NOT NULL,
metric_type TEXT NOT NULL, -- agent_success | gate_trigger | delegation_depth
agent_id TEXT,
value REAL NOT NULL,
metadata TEXT -- JSON for additional context
);
Example Metrics
- agent_success: value=1.0 for successful tool execution, 0.0 for failure
- gate_trigger: value=1.0 each time a human_gate is triggered
- delegation_depth: value=N for delegation at depth N
- circuit_break: value=1.0 each time autonomy depth exhausted
- confidence_score: value=0.0-1.0 from conductor confidence signal
3.9 Environment-Aware Policy
Detects environment from hostname or GOVERNANCE_ENV env var, loads base policy
from governance-policy.yaml, then applies environment-specific overrides from
state/env-overrides/<env>.yaml. Enables different retention policies,
gate enforcement modes, and alerting configs per environment.
# state/env-overrides/production.yaml
retention:
audit_events:
retention_days: 365 # Override from base 90 days
metrics:
retention_days: 730
alerting:
enabled: true
webhook:
enabled: true
url: "https://n8n.example.com/webhook/governance"
syslog:
enabled: true
host: "siem.example.com"
port: 514
Centralized Policy (Single Source of Truth)
All governance components reference state/governance-policy.yaml. No scattered config files.
Tool tiers, classification patterns, gate rules, tier matrix, and retention policies all in one place.
3.10 Non-Human Identity (NHI) Instance Tracking
Every agent invocation receives a unique Non-Human Identity (NHI) instance ID following the pattern
nhi_{agent}_{YYYYMMDD}_{hex8}. This extends the manifest system from static identity
to per-invocation lifecycle tracking — enabling audit correlation, cost attribution, and
forensic reconstruction of multi-agent workflows.
NHI Lifecycle
| Event |
Trigger |
Audit Type |
Data Recorded |
| Spawn |
Task tool dispatches agent |
NHI_SPAWN |
nhi_id, agent_id, parent_nhi_id, manifest_id, spawn timestamp |
| Active |
Agent executing tools |
— |
All tool events tagged with nhi_id |
| Terminate |
Task completes or fails |
NHI_TERMINATE |
nhi_id, exit_reason (success/failure/timeout), duration, tool_count |
# NHI ID generation (in pre_tool_check.py)
import secrets, datetime
def generate_nhi_id(agent_id: str) -> str:
date = datetime.datetime.utcnow().strftime("%Y%m%d")
hex8 = secrets.token_hex(4)
return f"nhi_{agent_id}_{date}_{hex8}"
# Example: nhi_security-analyst_20260317_a4f8d2c1
NHI IDs propagate through delegation chains. When a parent agent spawns a child via the Task tool,
the child's NHI_SPAWN event records parent_nhi_id, creating a traceable
invocation tree. The conductor's agent_instances registry in state tracks all active NHIs.
3.11 MCP Firewall (DLP Screening)
External MCP tool calls (mcp__*) pass through a Data Loss Prevention (DLP) firewall
before execution. The firewall intercepts all MCP tool inputs in the PreToolUse hook and scans
content against classification patterns to prevent sensitive data exfiltration to external services.
MCP Firewall Decision Matrix
| Content Classification |
Action |
Audit Event |
Severity |
| Restricted |
Block — hard stop |
DLP_VIOLATION |
critical |
| Confidential |
Block — require human approval |
DLP_VIOLATION |
high |
| Internal |
Allow with audit trail |
TOOL_ALLOWED (logged) |
— |
| Public |
Allow |
— |
— |
# MCP Firewall (in pre_tool_check.py)
def _check_mcp_firewall(tool_name, tool_input, manifest, threat_detector, audit_bus):
"""Block MCP tools from exfiltrating classified data."""
if not tool_name.startswith("mcp__"):
return None # Not an MCP tool
# Extract MCP server name for audit trail
parts = tool_name.split("__")
mcp_server = parts[1] if len(parts) >= 2 else "unknown"
# Run DLP scan against classification patterns
detection = threat_detector.scan_mcp_input(tool_name, tool_input, manifest)
if detection.detected:
audit_bus.emit(EventType.DLP_VIOLATION, manifest,
tool_name=tool_name, outcome="block",
detail={"mcp_server": mcp_server, ...detection})
return {"decision": "block", "reason": detection.detail}
return None # Allow
3.12 Last-Hop Validation
PostToolUse hook validates that Bash commands containing external connectivity tools
(ssh, curl, wget, psql, mysql,
redis-cli) target approved destinations. Prevents agents from establishing
unauthorized external connections even when the command itself passes PreToolUse policy checks.
Detection Pattern
The validator extracts destination hostnames and IPs from command arguments using regex patterns.
These are compared against an allowlist in governance-policy.yaml. Connections to
unlisted destinations emit LAST_HOP_VIOLATION audit events with the extracted
destination for forensic review.
# Last-hop validation (in output_validator.py)
EXTERNAL_TOOLS = re.compile(
r'\b(ssh|curl|wget|psql|mysql|redis-cli)\b')
def _check_last_hop(command: str, manifest: dict, audit_bus) -> Optional[str]:
"""Validate external connection destinations."""
if not EXTERNAL_TOOLS.search(command):
return None
# Extract destination (hostname/IP after tool keyword)
destinations = _extract_destinations(command)
allowed = load_allowed_destinations()
for dest in destinations:
if dest not in allowed:
audit_bus.emit(EventType.LAST_HOP_VIOLATION, manifest,
tool_name="Bash", outcome="warn",
detail={"command_tool": match, "destination": dest})
return f"Unrecognized destination: {dest}"
return None
3.13 Prohibited Behavior Monitoring
Hard-coded kill switches for behaviors that should never occur in any context, regardless of
manifest permissions or trust level. Unlike policy engine rules (which can vary by tier),
prohibited behaviors are absolute — no override, no exception, no human approval path.
Prohibited Behaviors
- Network tunneling —
ssh -L, ssh -R, ssh -D, socat, ncat tunnel creation
- Credential exfiltration — reading
.env, credentials.json, .signing-key and sending externally
- Audit trail modification — any
DELETE or UPDATE on audit.db, audit-buffer.jsonl
- Unauthorized API calls — direct HTTP calls to governance/conductor internal endpoints
Enforcement
- Pattern matching in PreToolUse (before policy engine)
- Emits
PROHIBITED_BEHAVIOR audit event
- Always severity
critical
- Always outcome
block
- Cannot be overridden by manifest permissions
- Cannot be approved via human gate
3.14 External Audit Sink
Critical governance events are emitted to an external syslog endpoint (Wazuh compatible)
in addition to the local SQLite audit bus. This provides a tamper-resistant audit trail —
even if an agent compromises the local audit.db, the external copy persists.
Sink Architecture
The audit bus's alerting callback (Section 3.7) is extended to emit all security-relevant
events to syslog, not just the 5 alert types. Events flow: governance hook → audit_bus.emit() →
SQLite WAL → alerting callback → syslog UDP. The sink is fail-open — syslog delivery
failures never block governance operations. A local buffer at state/syslog-buffer.jsonl
captures events during syslog outages for replay.
Defense in Depth
Local audit (SQLite) + external audit (syslog/Wazuh) + metrics (separate SQLite) creates
three independent records of governance activity. An attacker would need to compromise all three
simultaneously to erase evidence.
3.15 Cost Tracking (Denial of Wallet)
Tracks token consumption per agent invocation and per workflow to prevent runaway costs.
Each NHI instance accumulates token counts (input + output) from tool calls. When cumulative
cost exceeds configurable thresholds, the system halts the workflow and escalates to the operator.
Cost Thresholds
| Scope |
Threshold |
Action |
Audit Event |
| Per-agent invocation |
Configurable (default: 100K tokens) |
Warn at 80%, halt at 100% |
COST_THRESHOLD |
| Per-workflow total |
Configurable (default: 500K tokens) |
Warn at 80%, halt at 100% |
COST_THRESHOLD |
| Per-session |
Configurable (default: 1M tokens) |
Hard stop, require restart |
COST_THRESHOLD |
Cost data is recorded in conductor-state.json under the cost_tracking property,
which includes token_budget, tokens_used, cost_estimate_usd,
and halt_on_exceed flag. The conductor orchestrator checks thresholds before each agent dispatch.
3.16 Cryptographic Bill of Materials (C-BOM)
The CISO agent generates a Cryptographic Bill of Materials — a comprehensive inventory of all
cryptographic implementations in the target project. This addresses post-quantum cryptography (PQC)
readiness assessment and crypto-agility requirements from frameworks like NIST SP 800-131A and
the NSA CNSA 2.0 suite.
C-BOM Inventory Scope
| Category |
What's Inventoried |
PQC Risk Level |
| Symmetric encryption |
AES modes, key sizes, implementations |
Low (quantum-resistant) |
| Asymmetric encryption |
RSA, ECDSA, Ed25519 key sizes and usage |
Critical (quantum-vulnerable) |
| Hash functions |
SHA-256, SHA-3, HMAC implementations |
Low-Medium |
| Key exchange |
DH, ECDH, X25519 protocols |
Critical (quantum-vulnerable) |
| TLS/mTLS |
Protocol versions, cipher suites, certificate chains |
Varies by suite |
| Random number generation |
CSPRNG usage, entropy sources |
Low |
The C-BOM output includes a PQC readiness assessment table mapping each crypto implementation to its
NIST PQC migration priority (Harvest Now/Decrypt Later risk), recommended quantum-safe alternative
(ML-KEM, ML-DSA, SLH-DSA), and estimated migration effort. This is stored in
conductor-state.json under project_characteristics.crypto_implementations
and project_characteristics.pqc_readiness.