1. Problem Statement
The core challenge: AI-generated code ships with significant quality and security deficits. Studies show up to 62% dead code and duplication in AI-assisted codebases, with 40% containing known security vulnerabilities. There is no unified assurance layer that combines code quality, security scanning, testing adequacy, supply chain integrity, and compliance reporting into a single pipeline.
The result: teams either skip quality checks entirely (shipping vulnerable code) or cobble together ad-hoc tool chains that produce thousands of unranked findings, most of which are false positives. Developers lose trust in the tooling and stop paying attention to findings.
What you need:
- Unified scanning across 6 pillars (quality, security, testing, performance, supply chain, policy) with a single command
- Intelligent finding enrichment that eliminates false positives through 6 stages of progressive analysis
- Quantitative scoring that gives every codebase a comparable quality number (0–1000)
- Cryptographic attestation that proves what was scanned, when, by whom, with what results
- Multiple integration methods — MCP server, CLI skill, REST API, n8n workflows, or natural language
2. Architecture Overview
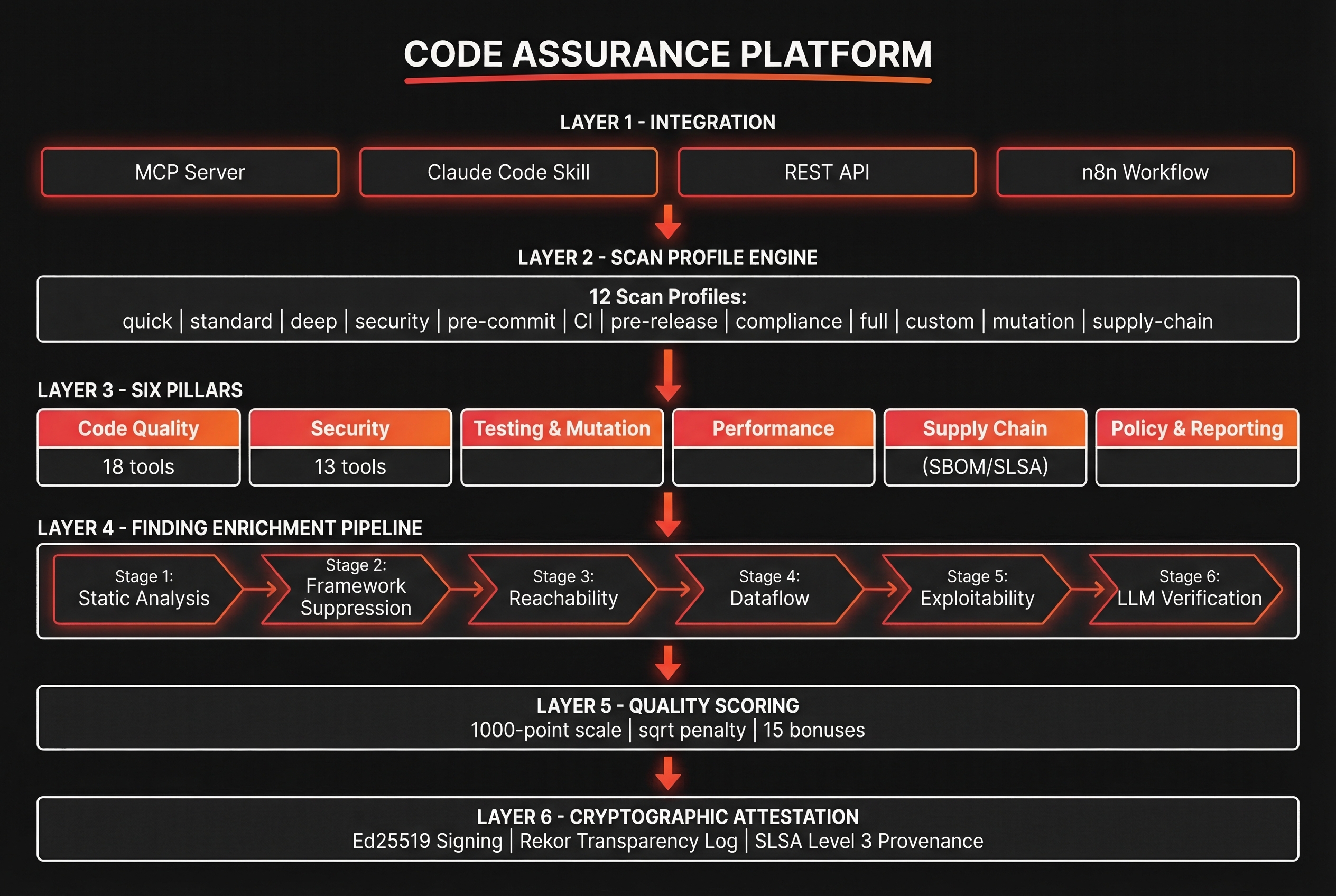
3. Key Components
3.1 Scan Profile Engine
The profile engine determines which tools run, at what depth, and with what thresholds. 12 predefined profiles cover the full spectrum from rapid pre-commit checks to exhaustive compliance audits.
| Profile | Tools Active | Duration | Use Case |
|---|---|---|---|
quick | 8–12 | < 30s | Developer desktop, rapid feedback |
standard | 25–35 | 1–3 min | Default scan for most workflows |
deep | 50–67 | 5–15 min | Thorough analysis, all tools enabled |
security-focused | 20–30 | 2–5 min | Security tools only, deep analysis |
pre-commit | 5–8 | < 10s | Git hook, staged files only |
ci-pipeline | 30–45 | 3–8 min | CI/CD integration with SARIF output |
pre-release | 55–67 | 10–20 min | Release candidate validation |
compliance | 40–55 | 5–10 min | Regulatory compliance checks |
performance | 10–15 | 2–5 min | Performance-specific analysis |
supply-chain | 8–12 | 1–3 min | Dependency and SBOM focused |
custom | Variable | Variable | User-defined tool selection |
full-audit | 67 | 15–30 min | Complete audit with attestation |
3.2 Code Quality Analysis
Combines 10 custom AI-powered analyzers with 8 established open-source tools for comprehensive code quality assessment.
AI Analyzers (10)
- Dead code detection
- Duplication analysis
- Complexity scoring
- Naming convention audit
- Error handling review
- API contract validation
- Type safety analysis
- Documentation completeness
- Pattern conformance
- Architectural boundary check
OSS Tools (8)
- ESLint (JavaScript/TypeScript)
- Pylint (Python)
- Ruff (Python, fast linting)
- Clippy (Rust)
- golangci-lint (Go)
- SonarScanner (multi-language)
- PMD (Java)
- ShellCheck (Bash/Shell)
3.3 Security Scanning
13 security-focused tools covering SAST, secret detection, dependency vulnerabilities, container scanning, and API security.
| Tool | Category | Coverage |
|---|---|---|
| Semgrep | SAST | Multi-language pattern matching with custom rules |
| Trivy | Vulnerability | OS packages, language deps, container images, IaC |
| Bandit | SAST (Python) | Python-specific security anti-patterns |
| Gitleaks | Secret Detection | API keys, tokens, passwords in source and history |
| Bearer | Secret/API | Sensitive data flows and API security |
| Checkov | IaC Security | Terraform, CloudFormation, Kubernetes configs |
| Grype | Vulnerability | Container image and filesystem vulnerability scanning |
| OSV-Scanner | Vulnerability | Google's open source vulnerability database |
| njsscan | SAST (Node.js) | Node.js/Express specific security patterns |
| gosec | SAST (Go) | Go-specific security analysis |
| cargo-audit | Vulnerability | Rust crate vulnerability scanning |
| pip-audit | Vulnerability | Python package vulnerability scanning |
| npm audit | Vulnerability | Node.js dependency vulnerability scanning |
3.4 Testing & Mutation
Beyond test execution, mutation testing validates that your test suite actually catches bugs. Mutants are generated, and tests that fail to detect them reveal weak spots.
Test Runners
- Jest (JavaScript/TypeScript)
- Pytest (Python)
- Go test (Go)
- Cargo test (Rust)
Mutation Engines
- Stryker (JS/TS — 30+ mutators)
- mutmut (Python)
- Pitest (Java/JVM)
- Coverage gap analysis
3.5 Supply Chain Assurance
Full software supply chain integrity from dependency analysis to cryptographic signing and provenance tracking.
- SBOM Generation — Syft and cdxgen produce Software Bills of Materials in CycloneDX and SPDX formats
- Sigstore Signing — Keyless code signing via Sigstore with transparency log entries
- SLSA Provenance — SLSA Level 3 provenance attestations documenting the build pipeline
- Dependency Analysis — Transitive dependency resolution with license compliance checking
- Reproducible Builds — Build environment attestation for audit and verification
3.6 Finding Enrichment Pipeline
Raw tool output is noise. The 6-stage enrichment pipeline transforms thousands of findings into a ranked, actionable set with near-zero false positives.
Static Analysis
Aggregate raw findings from all active tools. Normalize format, deduplicate by location and type, assign initial severity based on tool confidence.
Framework-Aware Suppression
Suppress findings that are false positives in the context of known frameworks. Django ORM queries aren't SQL injection. React's dangerouslySetInnerHTML with sanitized input isn't XSS.
Reachability Analysis
Trace call paths from entry points to vulnerable code. If no execution path reaches the finding, downgrade severity. Dead code vulnerabilities are informational, not critical.
Dataflow Tracing
Track tainted data from sources (user input, API responses, file reads) through transforms to sinks (database queries, system commands, network calls). Only flag findings where tainted data reaches a sink without sanitization.
Exploitability Scoring
Assign EPSS-style exploitability scores based on attack surface exposure, authentication requirements, network accessibility, and known exploit availability.
LLM-Assisted Verification
For findings that survive stages 1–5, use an LLM to review the surrounding code context and make a final determination. Can generate proof-of-concept exploits or confirm safe usage patterns.
3.7 Quality Scoring
Every scan produces a composite quality score on a 1000-point scale. The scoring algorithm uses a square-root penalty curve — early findings cost more, preventing "good enough" complacency.
Base Score Calculation
Start at 1000. Deduct points per finding: penalty = weight × sqrt(count). The sqrt curve means the first critical finding costs ~31 points, but 10 critical findings cost ~100 (not 310).
| Severity | Weight | 1 Finding | 5 Findings | 10 Findings |
|---|---|---|---|---|
| Critical | 31 | -31 | -69 | -98 |
| High | 18 | -18 | -40 | -57 |
| Medium | 8 | -8 | -18 | -25 |
| Low | 3 | -3 | -7 | -9 |
| Info | 1 | -1 | -2 | -3 |
Bonus Categories (15)
Positive quality signals add up to 150 bonus points across 15 categories: test coverage (>80%), zero critical findings, complete documentation, no dead code, SBOM present, all dependencies up-to-date, mutation score >60%, no secrets detected, supply chain signed, SLSA attestation, performance thresholds met, accessibility compliance, license compliance, code review completed, and CI/CD integration active.
3.8 Cryptographic Attestation
Every scan result can be cryptographically signed to create a tamper-proof record of what was scanned, when, and what was found.
- Ed25519 Signing — Fast, secure digital signatures on scan results and quality scores
- Rekor Transparency Log — Append-only public ledger via Sigstore Rekor for audit trail
- SLSA Provenance — Level 3 provenance documents linking code to scan results to build artifacts
- Verification CLI —
hardener verify <attestation-id>confirms integrity against transparency log
3.9 Integration Methods
Five integration methods ensure the platform fits into any development workflow:
| Method | Interface | Best For |
|---|---|---|
| MCP Server | Model Context Protocol | Claude Code direct integration, real-time scanning during development |
| Claude Code Skill | Slash command (/harden) | Developer-initiated scans with natural language configuration |
| REST API | HTTP endpoints | CI/CD pipelines, webhook integration, custom tooling |
| n8n Workflows | n8n nodes | Automated scan pipelines, scheduled audits, notification flows |
| Natural Language | Chat interface | Ad-hoc queries: "scan this repo for security issues" or "what's the quality score?" |
3.10 Reporting
Scan results are available in 5 output formats with executive summaries for non-technical stakeholders.
Output Formats
- PDF (executive summary + details)
- JSON (machine-readable, full data)
- HTML (interactive, filterable)
- SARIF (IDE/CI integration)
- CSV (spreadsheet analysis)
Report Sections
- Executive summary with quality score
- Finding breakdown by pillar
- Trend analysis (score over time)
- Remediation guidance per finding
- Attestation verification status
4. Requirements
quick profile SHALL complete in under 30 seconds for repositories under 50K lines5. Prompt to Build It
Build a unified code assurance platform (Code Hardener) that scans codebases across 6 pillars:
Code Quality, Security, Testing, Performance, Supply Chain, and Policy/Reporting.
Architecture:
- 12 scan profiles (quick, standard, deep, security-focused, pre-commit, ci-pipeline,
pre-release, compliance, performance, supply-chain, custom, full-audit)
- Each profile is a YAML file declaring active tools, depth, and thresholds
- Tool execution is parallelized with dependency-aware scheduling
Code Quality Pillar:
- 10 AI-powered analyzers: dead code, duplication, complexity, naming, error handling,
API contracts, type safety, documentation, pattern conformance, architectural boundaries
- 8 OSS tools: ESLint, Pylint, Ruff, Clippy, golangci-lint, SonarScanner, PMD, ShellCheck
Security Pillar:
- 13 tools: Semgrep (SAST), Trivy (vuln/container), Bandit (Python SAST),
Gitleaks (secrets), Bearer (API/secrets), Checkov (IaC), Grype (container),
OSV-Scanner (vuln DB), njsscan (Node SAST), gosec (Go SAST),
cargo-audit (Rust), pip-audit (Python), npm audit (Node)
Testing Pillar:
- Test runners: Jest, Pytest, go test, cargo test
- Mutation engines: Stryker (JS/TS), mutmut (Python), Pitest (Java)
- Coverage gap analysis with mutation score tracking
Supply Chain Pillar:
- SBOM: Syft + cdxgen (CycloneDX and SPDX output)
- Signing: Sigstore keyless signing
- Provenance: SLSA Level 3 attestations
- License compliance checking
Finding Enrichment Pipeline (6 stages):
1. Static Analysis - aggregate, normalize, deduplicate raw findings
2. Framework-Aware Suppression - suppress known false positives for Django, React, etc.
3. Reachability Analysis - trace call graphs, downgrade unreachable findings
4. Dataflow Tracing - track tainted data source-to-sink
5. Exploitability Scoring - EPSS-style scoring (attack surface, auth, known exploits)
6. LLM-Assisted Verification - final review with code context
Quality Scoring (1000-point scale):
- Base: 1000 minus sqrt-weighted penalties per severity
- Weights: Critical=31, High=18, Medium=8, Low=3, Info=1
- Formula: penalty = weight * sqrt(finding_count)
- 15 bonus categories (up to +150): test coverage >80%, zero criticals,
complete docs, no dead code, SBOM present, deps current, mutation >60%,
no secrets, supply chain signed, SLSA attestation, perf thresholds,
accessibility, license compliance, code review done, CI/CD active
Cryptographic Attestation:
- Ed25519 signing of scan results
- Rekor transparency log integration
- SLSA Level 3 provenance generation
- Verification CLI: hardener verify <attestation-id>
Integration Methods:
- MCP server (for Claude Code)
- Claude Code skill (/harden slash command)
- REST API with OpenAPI spec
- n8n workflow nodes
- Natural language interface
Reporting: PDF, JSON, HTML, SARIF, CSV with executive summaries
Governance: emit audit events for the governance framework
Memory: store scan results in vector memory for trend analysis6. Design Decisions
Tool Orchestration: Parallel with Dependency Graph
Decision: Run tools in parallel using a dependency-aware scheduler rather than sequentially.
Trade-off: Higher memory usage but significantly faster scans. A full-audit scan with 67 tools completes in 15–30 minutes instead of 2+ hours sequential. Tool dependencies (e.g., SBOM must complete before license checking) are modeled as a DAG.
Scoring Algorithm: Square-Root Penalty Curve
Decision: Use sqrt(count) rather than linear penalties.
Trade-off: A codebase with 1 critical and 100 low findings scores differently than 100 criticals and 1 low. The sqrt curve prevents "why bother" despair from high finding counts while still penalizing the first findings heavily. The first critical finding is more impactful to your score than the 10th.
Enrichment Pipeline: 6 Stages over 3
Decision: Invest in 6 enrichment stages rather than simpler 3-stage filtering.
Trade-off: The pipeline adds processing time (30s–2min per stage) but reduces false positive rates from typical 60–80% to under 5%. The LLM verification stage (Stage 6) is the most expensive but catches context-dependent patterns that static analysis cannot.
Self-Hosted vs SaaS: Self-Hosted First
Decision: Design for self-hosted deployment with Docker Compose, SaaS as optional future layer.
Trade-off: More operational overhead but no data leaves the organization. Source code never touches external servers. Critical for enterprises with strict data residency requirements. The containerized architecture means tools are version-locked and reproducible.
7. Integration Points
Governance Framework
The code assurance platform emits audit events to the governance framework's event bus. Every scan produces scan_initiated, scan_completed, and attestation_created events. Quality scores below configured thresholds trigger policy_violation events that can block deployments.
Multi-Agent Orchestration
The conductor's QA tier integrates directly with the code assurance platform. When the conductor classifies a task as STANDARD or MAJOR, it automatically triggers a scan at the appropriate profile depth. The QA agent reviews findings and can request code modifications before approving the task.
Persistent Memory System
Scan results are stored in the vector memory system for trend analysis. Over time, the system builds a knowledge base of common findings, successful remediations, and quality trajectories. Memory queries like "what security findings have we seen in authentication code?" return contextualized results.
Plugin Ecosystem
The code assurance platform integrates via the plugin hook system. PreToolUse hooks can trigger pre-commit scans. PostToolUse hooks can validate that file modifications don't introduce new findings. Custom skills expose scanning capabilities through slash commands.
Context Management
Scan profiles and quality thresholds can be configured per-project via CLAUDE.md or project-level configuration. The context system ensures that the right scan profile is automatically selected based on the project's security requirements and compliance posture.